
This article is an extension of a presentation on mainframe resilience a colleague and I gave at the GS NL 2025 conference, in Almere on June 5, 2025.
Introduction
In this article, I will examine today’s challenges in IT Resilience and look at where we came from with mainframe technology. Today’s resilience is no longer just threatened by natural disasters or equipment failures. Today’s IT resilience must include measures to mitigate the consequences of cyberattacks, rapid changes in the geopolitical landscape, and the increasing reliance on IT services by international dependencies.
IT resilience is more important than ever. Regulatory bodies respond to changes in these contexts more quickly than ever. Yet our organizations should be able to anticipate these changes more effectively. Where a laid-back organizational ‘minimum viable solution’ approach was taken, the speed of change drives us to more actively anticipate changes, and cater for disaster scenarios before regulatory bodies force us to. And suppose you are not in an organization that is regulated. In that case, you may still need to pay close attention to what is happening to safeguard your continued market position and even the existence of your organization.
In this article, I will discuss some areas where we can improve the technical capabilities of the mainframe. As we will see, the mainframe’s centralized architecture is well-positioned to further strengthen its position as the most advanced platform for data resilience.
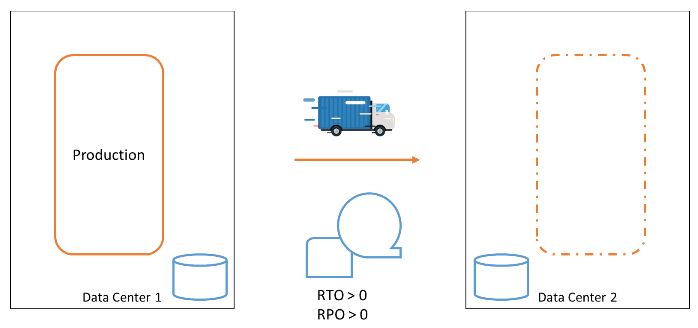
A production system and backups
Once we had a costly computer system. We stored our data on an expensive disk. Disk crashes were regularly happening, so we made backups on tape. When data was lost or corrupted, we restored it from the tape. When a computer crashed, we recovered the system and the data from our backups. Of course, downtimes would be considerable – the mean time to repair, MTTR, was enormous. The risk of data loss was significant: the recovery point objective, RPO, was well over zero.

A production system and a failover system
At some point, the risk of data loss and the time required to recover our business functions in the event of a computer failure became too high. We needed to respond to computer failures faster. A second data center was built, and a second computer was installed in it. We backed up our data on tape and shipped a copy of the tapes to the other data center, allowing us to recover from the failure of an entire data center.
We still had to make backups at regular intervals that we could fall back to, leaving the RPO still significantly high. But we had better tolerance against equipment failures and even entire data center failures.
Our recovery procedures became more complex. It was always a challenge to ensure our systems would be recoverable in the secondary data center. The loss of data could not be prevented. The time it took to get the systems back up in the new data center was significant.
Clustering systems with Parallel Sysplex
In the 1990s, IBM developed a clever mechanism that creates a cluster of two or more MVS (z/OS) operating system images. This included advanced facilities for middleware solutions to leverage such a cluster and build middleware clusters with unparalleled availability. Such a cluster is called a Parallel Sysplex. The members—the operating system instances—of a Parallel Sysplex can be up to 20 kilometers apart. With these facilities, you can create a Parallel Sysplex that spans two (or more) physical data centers. Data is replicated synchronously between the data centers, ensuring that any change to the data on the disk in one data center is also reflected on the disk in the secondary data center.
The strength of the Parallel Sysplex is that when one member of the Parallel Sysplex fails, the cluster continues operating, and the user does not notice. An entire data center could be lost, and the cluster member(s) in the surviving data center(s) can continue to function.
With Parallel Sysplex facilities, a configuration can be created that ensures no disruption occurs when a component or data center fails, resulting in a Recovery Time Objective (RTO) of 0. This allows operation to continue without any loss of data, with a Recovery Point Objective (RPO) of 0.

Continuous availability with GDPS
In addition to the Parallel Sysplex, IBM developed GDPS. If you lose a data center, you eventually want the original Parallel Sysplex cluster to be fully recovered. For that, you would need to create numerous procedures. GDPS automates the task of failover for members in a sysplex and the recovery of these members in another data center. GDPS can act independently in failure situations and initiate recovery actions.
Thus, GDPS enhances the fault tolerance of the Parallel Sysplex and eliminates many tasks that engineers would otherwise have to execute manually in emergency situations.

Valhalla reached?
With GDPS, the mainframe configuration has reached a setup that could genuinely be called continuously available. So is this a resilience walhalla?
Unfortunately not.
The GDPS configuration also has its challenges and limitations.
Performance
The first challenge is performance. In the cluster setup, we want every change to be guaranteed to be made in both data centers. At any point in time, one entire data center could collapse, and still, we want to ensure that we have not lost any data. Every update that must be persisted must be guaranteed to be persisted on both sides. To achieve this, an I/O operation must not only be performed locally in the data center’s storage, but also in the secondary data center. Committed data can therefore only be guaranteed to be committed if the storage in the secondary data center has acknowledged to the first data center that an update has been written to disk.
To achieve this protocol, which we call synchronous data mirroring, a signal with the update must be sent to the secondary data center, and a confirmation message must be sent back to the primary data center.
Every update requires a round-trip, so the minimum theoretical latency due to distance alone is approximately 0.07 milliseconds—that is, the speed of light traveling 10 kilometers and back. In practice, actual update time will be higher due to network equipment latency, such as in switches and routers, protocol overhead, and disk write times. For a distance of 10 kilometers, an update could take between 1 and 2 milliseconds. This means for one specific application resource, you can only make 1000 to 500 updates per second. (Many resource managers, like database management systems, fortunately, provide a lot of parallelization in their updates.)
In other words, a Parallel Sysplex cluster offers significant advantages, but it also presents challenges in terms of performance. These challenges can be overcome, but additional attention is necessary to ensure optimal application performance, which comes at the cost of increased computing capacity required to maintain this performance.
Cyber threats
Another challenge has grown in our IT context nowadays: threats from malicious attackers. We have connected our IT systems to the Internet to allow our software systems to interact with our customers and partners. Unfortunately, this has also created an attack surface for individuals with malicious intent. Several types of cyberattacks have become a reality today, and cyber threats have infiltrated the realms of politics and warfare. Any organization today must analyse its cyber threat posture and defend against threats.
One of the worst nightmares is a ransomware attack, in which a hostile party has stolen or encrypted your organization’s data and will only return control after you have paid a sum of money or met their other demands.
The rock-bottom protection against ransomware attacks is to save your data in a secure location where attackers cannot access or manipulate it.
Enter Cybervault
A Cybervault is a solution that sits on top of your existing data storage infrastructure and backups. In a Cybervault, you store your data in a way that prevents physical manipulation: you create an immutable backup of your data.
In our mainframe setup, IBM has created a solution for this: IBM Z Cyber Vault. With IBM Z Cybervault, we add a third leg to our data mirroring setup, an asynchronous mirror. From this third copy of our data, we can create immutable copies. This solution combines IBM software and storage hardware. With IBM Z Cyber Vault, we can make a copy of all our data at regular intervals as needed. Typically, we can make an immutable copy every half hour or every hour. Some IBM Z users take a copy just once every day. This frequency can be configured. From every immutable copy, we can recover our entire system.
So now we have a highly available configuration, with a cyber vault that allows us to go back in time. Great. However, we still have more wishes on our list.

Application forward recovery
In the great configuration we have just built, we can revert to a previous state if data corruption is detected. When the corruption is detected at time Tx, we can restore our copy from time T0, the backup closest to the moment T1 of data corruption.

Data between the corruption at T1 and the detection at Tx is lost. But could we recover as much of the data that was still intact after the backup was made (T0) and before the corruption occurred (T1)?
Technically, it is possible to recover data in the database management system Db2 using the image copies and transaction logs that Db2 uses. With Db2 recovery tools, you can recover an image copy of a database and apply all changes from that backup point forward, using the transaction logs in which Db2 records all changes it makes. When we combine this technology with the Cybervault solution, we would need a few more facilities:
- A facility to store Db2 image copies and transaction logs. Immutable, of course.
- A facility to let Db2, when restored from some immutable copy, know that there are transaction logs and archive logs made in the future, to which it can perform a forward recovery.
That is work, but it is very feasible.

Now, we have reached a point where we have created a highly available configuration, with a cybervault that can recover from a point as close to the point of corruption as possible.
Adding Linux workloads
Most of today’s mainframe users run Linux workloads on the mainframe, besides the traditional z/OS workloads. These workloads are often as business-critical as the z/OS workload. Therefore, it is great that we can now also include Linux workloads, including OpenShift container-based workloads, in the superb resilience capabilities of IBM Z.

Challenges
As such, we have extended the best-in-class resilient platform. Unfortunately, we are pushed further to address today’s challenges.
What if your backup is too close to your primary data?
Data Centers 1 and 2, as discussed above, may be too close to each other. This is the case when a disaster can occur that affects operations in both data centers. These could include natural disasters, such as a power outage or a plane crash.
I have called them Data Centers so far. Yet, the more generic term in the industry is Availability Zones. An Availability Zone is a (part of) Data Center that has independent power, cooling, and security, just like a Data Center. When you spread your IT landscape over availability zones, or data centers across geographical distances, you put them in different Regions. Regions are geographic areas, often with different risk profiles for disasters.
The Data Centers, or Availability Zones, are relatively close together, especially in European organizations. They are in the same Region. With the recent changes in political and natural climate, large organizations are increasingly looking to address the risks in their IT landscape and add data center facilities in another Region.
Cross-region failover and its challenges
To cater to a cross-region failover, we need to change the data center setup.
With our GDPS technology, we can cater for this by adding a GDPS Global ‘leg’ to our GDPS setup. The underlying data replication is Global Mirror replication, asynchronous.

The setup in this last picture summarizes the state of the art of the basic infrastructure capabilities of the mainframe. In comparison to other computing platforms, including cloud, the IBM Z infrastructure technologies highlighted here provide a comprehensive resilience solution for all workloads on the platform. This simplifies the realization and management of the resilience solution.
More challenges
Yet, there remains enough to be decided and designed, such as:
- Are we going to set up a complete active-active configuration in Region B, or do we settle for a stripped-down configuration? Our business will need to decide whether to plan for a scenario in which our data center in Region A is destroyed and we cannot switch back.
- Where do we put our Cybervault? In one region, or in both?
- How do we cater for the service unavailability during a region switch-over? In our neat, active-active setup, we can switch between data centers without any disruption. This is not possible with a cross-region failover. Should we design a stand-in function for our most business-critical services?
- We could lose data between our regions. The data synchronization is asynchronous. How should we cater for this potential data loss?
When tackling questions about risk, it all begins with understanding the organization’s risk appetite: the level of risk the business is willing to accept as it works toward its objectives. Leadership teams must decide which risks are best handled through technical solutions. For organizations operating in regulated spaces, regulators set minimum standards.
The bottom line on mainframe resilience
No other computing platform offers the combination of capabilities described in this article: zero RTO/RPO clustering, automated failover, immutable cyber vaults, forward recovery, and cross-region replication, all integrated into a single platform.
The remaining questions are not technical. They are strategic: How much resilience does your organization need? What is your risk appetite? And how does your mainframe resilience strategy connect to your broader IT and cloud strategy?
These are exactly the kinds of decisions explored in my book Don’t Be Afraid of the Mainframe. Chapter 12 covers system management and availability in depth, while the strategic decision frameworks in Part 3 help you translate technical capabilities into business choices.